December 20, 2017
Unifying the theories of neural information encoding
Scientists at IST Austria and in Paris develop framework connecting and extending previous theories on how neurons in our sensory systems select and transmit information | New theory gives concrete predictions for previously unstudied coding regimes
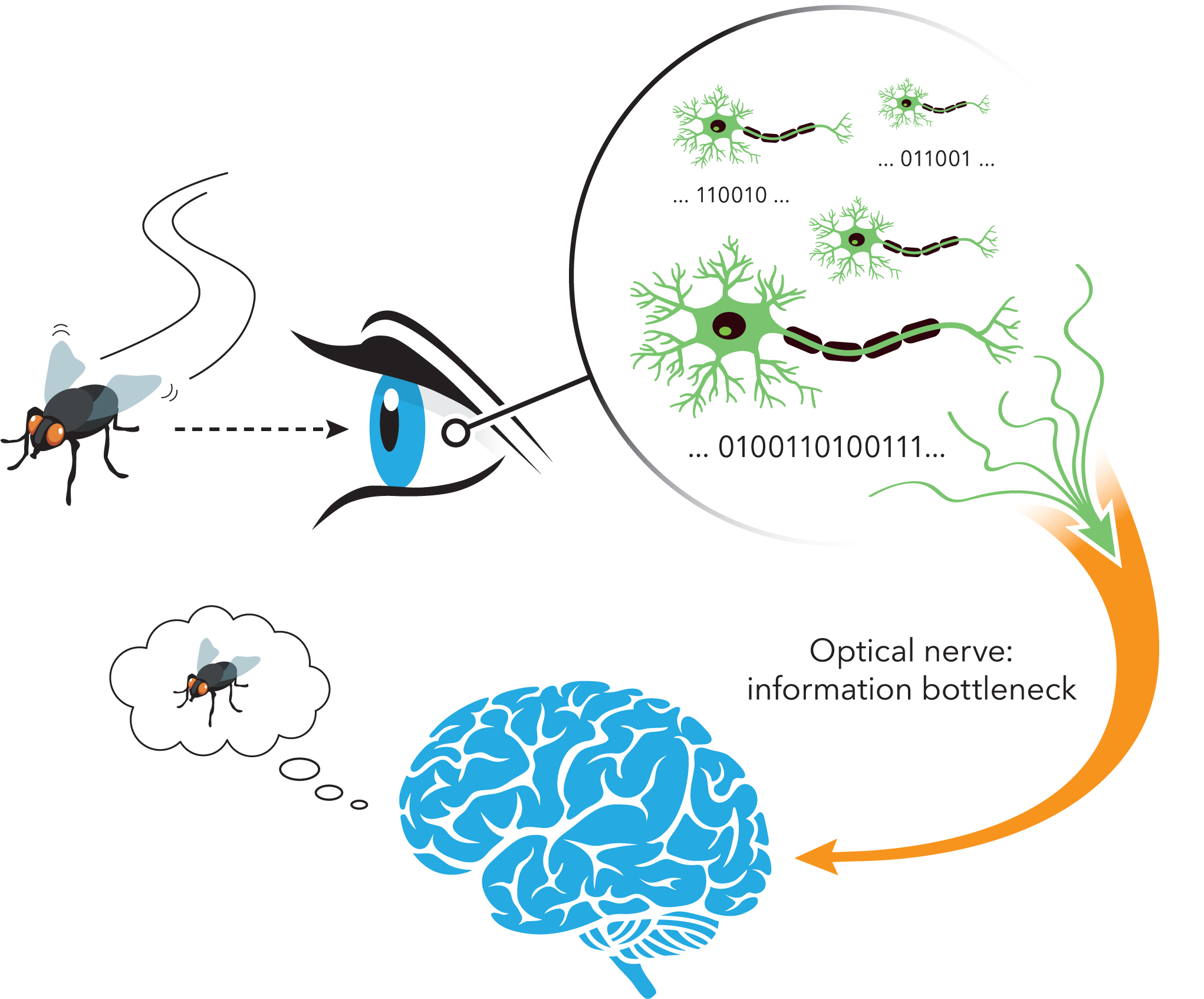
Digital video cameras have the capability to record in incredible detail, but saving all that data would take up a huge amount of space: how can we compress a video—that is, remove information—in such a way that we can’t see the difference when it is played back? Similarly, as we go about our daily lives, our eyes are flooded with visual information, but the neurons in our eyes have certain constraints—just like data engineers. Thus, given this rich set of stimuli, how do neurons select what to extract and send on to the brain? Neuroscientists have been asking this question for decades, and had previously used several different theories to explain and predict what neurons will do in certain situations. Now, Matthew Chalk (a former postdoc at IST Austria, currently at the Vision Institute in Paris), IST Austria Professor Gašper Tkačik, and Olivier Marre, who heads a retinal research lab at the Vision Institute, have developed a framework that unites the previous theories as special cases, and enables them to make predictions about types of neurons not previously described by any theory.
One of the main goals of sensory neuroscience is to predict neural responses using mathematical models. Previously, these predictions were based on three main theories, each of which had a different area of applicability, corresponding to varying assumptions about the neurons’ internal constraints, the type of signal, and the purpose of the gathered information. In general, a neural code is essentially a function that predicts when a neuron should “fire”, that is, emit an action potential signal much like a digital “1” in the binary alphabet that our computers use. Collections of one or more neurons firing at particular times can thus encode information. Efficient coding assumes that the neurons encode as much information as possible, given their internal constraints (noise, metabolism, etc.). Predictive coding, on the other hand, assumes that only the information relevant to predicting the future (e.g. which way an insect will fly) is encoded. Finally, sparse coding assumes that only a few neurons are active at any one time. One problem with this situation was that it was unclear how these theories were related, and if they were even consistent with each other. These latest developments bring order to the theoretical landscape: “Before, there was no clear notion of how to connect or compare these theories. Our framework overcomes this by fitting them together within an overarching structure,” says Gašper Tkačik.
In the context of the team’s framework, a neural code can be interpreted as the code that maximizes a certain mathematical function. This function—and thus, the neural code maximizing it—depends on three parameters: the noise in the signal, the goal or task (i.e. if the signal will be used to predict the future), and the complexity of the signal being encoded. The theories described above are valid only for specific ranges of values for these parameters and do not cover the entire possible parameter space, which presents problems when trying to test them experimentally. Gašper Tkačik explains: “When you design stimuli to present to the neurons to test your model, it is extremely difficult to distinguish between a neuron that is not fully consistent with your favorite theory or the alternative where your favorite theory is simply incomplete. Our unified framework can now give concrete predictions for parameter values that fall in between the previously studied cases.”
The team’s unified theory overcomes earlier limitations by allowing the neurons to have “mixed” coding objectives; they don’t have to fall into one clear, previously studied category. For example, the new theory can cover the case where neurons are individually very noisy but still should efficiently encode sparse stimuli. More generally, optimal neural codes can be placed on a continuum according the parameter values that define constraints to optimality, which explains phenomena that were previously observed, but not explained by any of the existing models. For first author Matthew Chalk, this is one of the most exciting contributions of their paper: “A lot of the theories that give predictions tend to be inflexible when tested: either it predicted the correct outcome or it didn’t. What we need more of, and what our paper provides, are frameworks that can generate hypotheses for a variety of situations and assumptions.”
In addition to endowing the theory with greater flexibility, their framework gives concrete predictions for types of neural encoding that were previously unexplored, for example encoding that is both sparse and predictive. To follow up on the theory developed in their paper, Matthew Chalk is designing experiments to test these predictions and help categorize neurons as efficient, predictive, or sparse—or as a combination of these coding objectives. In Olivier Marre’s lab at the Institut de la Vision in Paris, he focuses on the retina, and is developing visual stimuli that will activate retinal neurons so as to best reveal their coding objectives.
And the framework can also be applied more broadly: “You don’t necessarily need to think about neurons,” adds Gašper Tkačik. “The idea of framing this problem in terms of optimization can be used in any sort of signal processing system, and the approximation allows us to study systems that would normally have computationally intractable functions.” The three scientists laid the groundwork for further applications in a previous paper published in Advances in Neural Information Processing Systems (NIPS).
Sources
- Matthew Chalk, Olivier Marre, and Gašper Tkačik: “Towards a unified theory of efficient, predictive and sparse coding”, PNAS 2017
- Previous paper in NIPS: Matthew Chalk, Olivier Marre, and Gašper Tkačik: “Relevant sparse codes with variational information bottleneck”, NIPS 2016
- https://papers.nips.cc/paper/6101-relevant-sparse-codes-with-variational-information-bottleneck
