Research Data Management (RDM)
RDM is about taking care of your research data throughout the research lifecycle. It is the sum of many small and practical habits that occur before, during, and after a project. It includes all aspects of planning, documenting and organizing your data, defining how to handle sensitive data, thinking of backup and archive solutions during and after a project, as well as sharing your data properly so that it can be easily found and re-used. By considering these issues beforehand, you cover aspects of good scientific practice, ensure the reproducibility of your research, avoid data loss or creation of incomplete data, and plan for long-term preservation (e.g. re-usability in 10 years’ time). Moreover, many funders (like FWF or EC) require a Research Data Management Plan (RDMP) as mandatory, and almost all questions included in their RDMP templates (more information on RDMP) are dealt with in an accurate RDM.
On this site:
What is Research Data (RD)?
There is not one definition of what Research Data (RD) is, and it depends on the discipline in which data is collected. According to the OECD, “RD are defined as factual records (numerical scores, textual records, images, and sounds) used as primary sources for scientific research, and that are commonly accepted in the scientific community as necessary to validate research findings.” (OECD Principles and Guidelines for Access to Research Data from Public Funding, 2007, p. 13). The EU defines RD as “information, in particular facts or numbers, collected to be examined and considered as a basis for reasoning, discussion, or calculation. In a research context, examples of data include statistics, results of experiments, measurements, observations resulting from fieldwork, survey results, interview recordings and images.” (https://ec.europa.eu/research/participants/docs/h2020-funding-guide/cross-cutting-issues/open-access-data-management/open-access_en.htm).
What is the difference between FAIR data and Open data?
In many funder templates and publications regarding RDMP, you will find the acronyms FAIR data and Open data.
FAIR data stands for Findable, Accessible, Interoperable and Reusable data, it consists of 15 principles, which ensure readability for both humans and machines (see the publication of Wilkinson et al. for further details). Within Findable, the focus lies on rich metadata and unique, persistent identifiers. Accessible data implies that the metadata are understandable to humans and machines and that the dataset is stored in a trustworthy repository. To fulfill the principles within Interoperable, the metadata should be available in a broadly applicable language (so that you can re-use data interdisciplinary as well without knowing e.g. discipline specific abbreviations). Reusable means that data and data collections have a clear usage license and accurate information on provenance.
Therefore, to sum it up, the focus of FAIR lies on technical details and machine-readability. However, data/datasets can have a fine scale on how FAIR they are – this is not a yes/no switch.
Open data means that data should be freely available and accessible to everyone, free to reuse and redistribute, and that everyone must be able to use it (universal participation). There should be at least an open license or waivers; ideally, RD are also stored in an open format (non-proprietary), described in open standards, and linked to other data to provide context. As with FAIR, there is no binary choice but a scale of openness. When it comes to personal data protection, the motto is often described “as open as possible, as closed as necessary” (detailed information can be found in the section Legal/Ethical).
Your data can be FAIR and not open or the other way around. These principles are not excluding one another, and they are not in competition (read the article by Higman et al. (2019) for further details).
Keep in mind that neither Open nor FAIR has any statement regarding the quality of research data.
Research Data Lifecycle
The research data lifecycle is a model covering all stages necessary during a research project (depending on your research discipline). It illustrates that data have a much longer lifespan than only the duration of a project. This concept has become more important as data sharing increases.
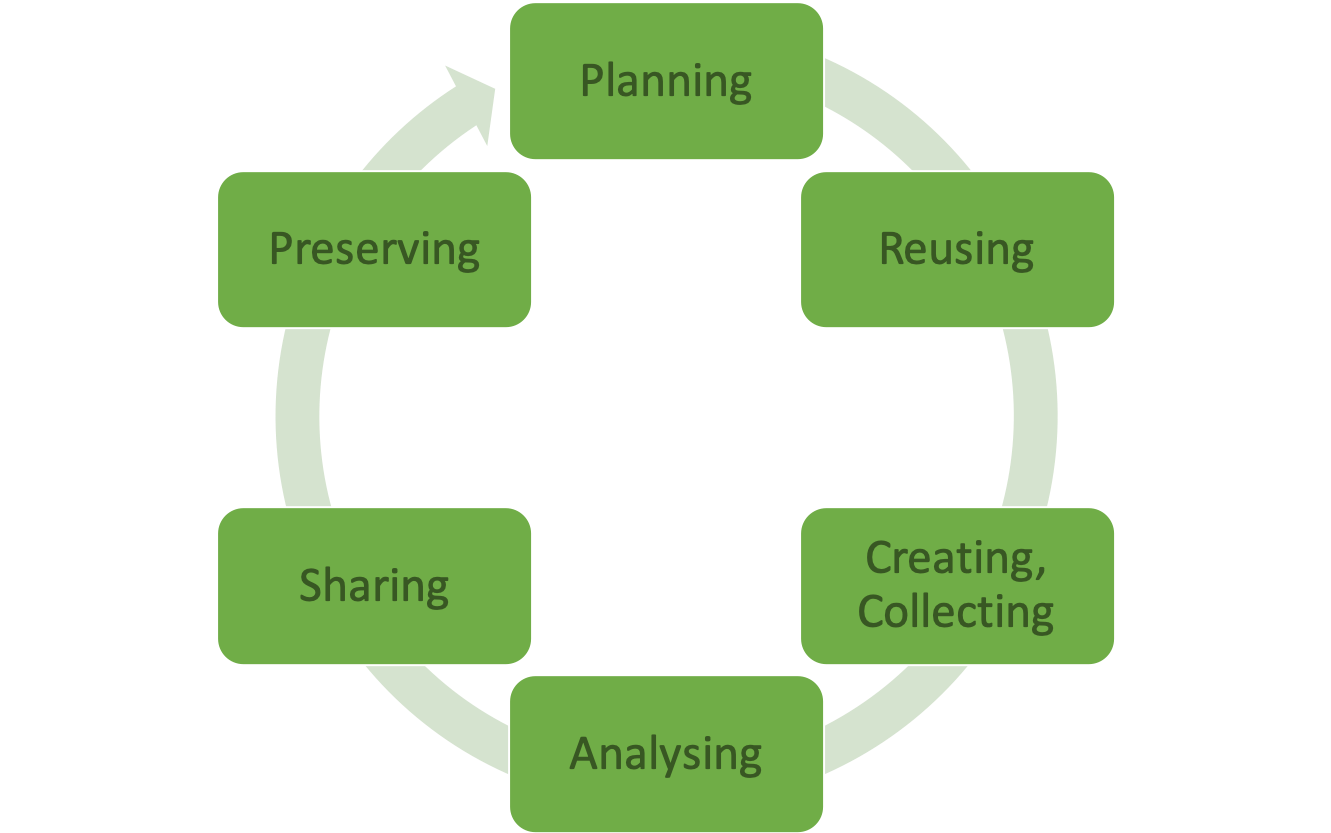
the University of Edinburgh, DCC, and RDNL https://www.futurelearn.com/courses/delivering-research-data-management-services
Planning
RDM includes far more than just writing a plan/answering a template to fulfill a funders requirement. It covers the activities you take to organize your data. Even so, a RDMP is a powerful tool to support you throughout a whole research project – in other words, RDM will make your daily business with data easier. The RDMP covers questions such as: how you will deal with your data, are you re-using already existing data or creating new one, who is working with them during the project, how is data documented, how is it stored, how is the backup been handled with, and which legal and ethical questions have to be considered.
ISTA Library provides a separate page dealing with all details on a RDMP. To support researchers further, ISTA implemented the RDMO tool, where you can organize your plans online on an ISTA server (ISTA login required).
Re-use of existing data
Before you start your research, consider if there are results and research datasets already available that you can re-use in your project (find further information on RDMP/re-using of data).
Creating and collecting data
In this stage, you perform your experiments, have your interviews, write your program, etc. All measurements and results are collected. Have a look at our hints for your documentation at the subpage RDMP/Documentation.
Processing and Analyzing
When processing your data, you will be entering, transcribing, checking, validating, and cleaning it; you may also need to anonymise your data. Furthermore, you should describe it and make sure it is properly managed and stored.
For analysing your data, you will be interpreting it and creating derived data and outputs; you will probably also author publications and prepare the data for deposit and sharing. Especially in these steps, a thorough documentation (see RDMP/Documentation for further details) is essential.
Sharing
Before you decide to share your data, you should consider copyrights, licenses and contracts as well as patents. Check additionally with institutional guidelines and policies.
You should share your RD for the following reasons:
- enlarge the visibility of your research
- receive more citations due to paper and data
- add the data citation in your CV
- find new collaborations through data sharing
- benefit from someone else’s data
- promote debate on research methods
- ensure validation, verification and replication of data
- can be used for teaching/learning
- required by some publishers and funders
- optimal use of publicly funded research
It may be that you share your data via a repository or handle access requests yourself. Either way, you need to establish copyright, decide who can have access, and promote the data (see RDMP/re-use for further information).
Preserving
Data repositories play a key role in preserving data: they will make sure that your research data is properly stored and archived, and they will create associated metadata. Some data repositories even offer to migrate the formats and storage medium as well as update the documentation to explain any changes made.
You can choose which kind of data repository is best for your data publication and preservation. There are discipline specific repositories or institutional ones. ISTA provides an institutional repository. To make data citations easier and ensure the permanent storage of data, every dataset receives an individual persistent identifier, in our case a DOI. The dataset is stored for at least 15 years (see RDMP/re-use for further information). If – for whatever reason – it is not possible to use a data repository, think about a local archiving system for your data that ensures sufficient backup options.
Legal and Ethical issues
Be aware of institutional, national and funder policies regarding sensitive research data. Think about the data you will create/collect in your research: are there any data protection issues involved? How do you ensure data anonymity and data confidentiality? Make sure you have these questions covered in your RDMP, especially if you have a collaboration between several institutions and/or countries with different (national/funder) regulations. For details on ethical issues, consider the information provided by EC for the 7th FP or ask our ISTA ethical officer.
Furthermore, there are copyright related topics to be considered. Primary research data (e.g.measurement data) itself is not affected by copyright, but is subject to the public domain. However, this changes as soon as it is processed (e.g. database right). Therefore, clarify ownership and rights of data you want to re-use before a project starts. For your own data, be specific what users are allowed to do if they want to re-use it (e.g. by using open licenses like CC0 or Open Data Commons).
Data security and backup
Even the best IT infrastructure does not help if you store your data only locally. Be aware and attentive of your own local computer security, and keep in mind that in 2019 the annual hard drive failure rate was at approx. 1,9% (https://www.backblaze.com/blog/hard-drive-stats-for-2019/). A natural disaster, theft, computer virus, or an accidental loss of data can happen to anyone. By using ISTA IT infrastructure, you minimize the risk of data loss. Together with IT, design a backup concept and test it before starting your project. Consider that not only digital but also analog data needs a backup! Consult the ISTA guidelines on how to handle research data and on good scientific record keeping before talking to IT.
Long-term storage and preservation
Consider beforehand what to do with your data after the active use will be over – this is an important decision of preserving data. Think about what would you need in a dataset so that you can re-use it without much effort. Choose open file formats (see RDMP/making data findable); prepare your documentation already during the project so that you will have just to update and finalize it before preservation. Remember to check on your long-term storage datasets every second year or so to see if they are still accessible/has data become corrupt/is the backup process still working correctly/etc.
Incentives for shared data
Add your shared data sets in your CV and your publication list just like a publication. Keep in mind that citation databases like Web of Science or Dimensions are also indexing RD. If you upload your RD to ISTA Research Explorer, you will receive a persistent identifier (DOI) for it. Consider also to publish a data paper (see RDMP/data accessible).
General Guidance
Thorough information on RDM and RDMPs, offers openly available RDMPs
further reading on RDM and RDMP available in the ISTA physical Library
Special information on Research Software Management Plans for software and code as well as general guidelines for good research software are collected by the Software Sustainability Institute.